|
|
You are here: Foswiki>AGLT2 Web>GlusterTesting (27 Jun 2012, BenMeekhof)Edit Attach
Testing Glusterfs
For testing purposes only we used the Redhat Storage Appliance demo which has gluster tools pre-installed. Docs are here: http://docs.redhat.com/docs/en-US/Red_Hat_Storage_Software_Appliance/3.2/pdf/User_Guide/Red_Hat_Storage_Software_Appliance-3.2-User_Guide-en-US.pdf The docs are largely a repeat of the documentation available from the gluster.org website. In any real usage scenario I would advise using the freely available gluster packages rather than this appliance. There does not seem to be any significant value in terms of ease of use or setup for purchasing the appliance though it would mean we would have full support for the gluster storage cluster. Cost per node is approximately $4000 and the minimum to start is 4 nodes. There is also a premium version for $6000 per node. This quote is from DLT Solutions who seems to work with the university or one may also want to email lsa.licensing to work with them in obtaining a license. I didn't attach the quote as I am not sure if it is ok to make that public.Upgrading gluster RPMS
As it turns out the RH appliance ships with version 3.2 of gluster. I wanted to test the most current version so I upgraded the system with v 3.3 RPMS from http://download.gluster.org/pub/gluster/glusterfs/3.3/LATEST/RHEL/ [root@umdist08 ~]# rpm -Uvh glusterfs-3.3.0-1.el6.x86_64.rpm glusterfs-geo-replication-3.3.0-1.el6.x86_64.rpmglusterfs-fuse-3.3.0-1.el6.x86_64.rpm glusterfs-server-3.3.0-1.el6.x86_64.rpm The glusterfs RPM obsoletes/replaces gluster-core from version 3.2. It should be noted that the version 3.2 server was not compatible with the version 3.3 client. Noticing that was what led to updating the server. Also note that the update lost my volume but it appeared to simply be a case of some config not being copied from an old config dir to a new one (the -server rpm post-install tried but failed because the destination existed from one of the other RPMS). Things moved from /etc/glusterd to /var/lib/glusterd. The meta-data was still on the brick and I'm pretty sure a real update in production following a more careful procedure would be fairly simple (especially if not a major version upgrade).System Configuration
3 x md1200 shelves, 3TB disks attached to Perc H800 controller. Created 3 RAID6 volumes, 12 disks each. Adaptive Read-ahead, Write back, 512KB stripe width. Created 3 XFS filesystems:mkfs.xfs -f -L glfs_sdc -d su=512k,sw=10 -l su=256k /dev/sdcMounted with inode64:
LABEL=glfs_sdc /glfs1 xfs inode64 1 1Later we need more volumes so for the replicated tests so 6 RAID5 volumes were set up and filesystems done as such:
mkfs.xfs -f -L glfs_sdd -d su=512k,sw=5 -l su=256k /dev/sddIozone tests done with iozone-3.394-1.el5.rf.x86_64 from DAG repository.
Gluster Configurations
We started with a simple volume using one hardware raid volume. Effectively a distributed volume with only 1 member:[root@umdist08 RHEL6]# gluster volume create testvolume umdist08:/glfs1 Creation of volume testvolume has been successful. Please start the volume to access data. [root@umdist08 RHEL6]# gluster volume info Volume Name: testvolume Type: Distribute Status: Created Number of Bricks: 1 Transport-type: tcp Bricks: Brick1: umdist08:/glfs1 [root@umdist08 RHEL6]# gluster volume start testvolume Starting volume testvolume has been successfulOther volumes were created as such:
6 Brick distributed replicated
[root@umdist08 ~]# gluster volume create test replica 2 transport tcp umdist08:/glfs1 umdist08:/glfs3 umdist08:/glfs6 umdist08:/glf s2 umdist08:/glfs4 umdist08:/glfs5 Multiple bricks of a replicate volume are present on the same server. This setup is not optimal. Do you still want to continue creating the volume? (y/n) y Creation of volume test has been successful. Please start the volume to access data.Checking status:
[root@umdist08 ~]# gluster volume status Status of volume: test Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick umdist08:/glfs1 24009 Y 2149 Brick umdist08:/glfs3 24010 Y 2155 Brick umdist08:/glfs6 24011 Y 2160 Brick umdist08:/glfs2 24012 Y 2167 Brick umdist08:/glfs4 24013 Y 2173 Brick umdist08:/glfs5 24014 Y 2179 NFS Server on localhost 38467 Y 2186 Self-heal Daemon on localhost N/A Y 2192
Client Setup
There are RPMS available for EL6 and others here: http://download.gluster.org/pub/gluster/glusterfs/LATEST/ For our SL5 test system dc2-3-35 I built RPMS from the spec included in the source download after installing some prerequisites:[root@c-3-35 glusterfs-3.3.0]# yum install flex libtool ncurses-devel readline-devel libibverbs-devel [root@c-3-35 glusterfs-3.3.0]# cp ../glusterfs-3.3.0.tar.gz /usr/src/redhat/SOURCES/ [root@c-3-35 glusterfs-3.3.0]# rpmbuild -ba glusterfs.specThen installed glusterfs-3.3.0-1.x86_64.rpm and glusterfs-fuse-3.3.0-1.x86_64.rpm Mounted at the command line:
[root@c-3-35 x86_64]# mount -t glusterfs -o log-level=WARNING,log-file=/var/log/gluster.log umdist08:/testvolume /mnt/gfs glusterfs#umdist08:/testvolume 28T 33M 28T 1% /mnt/gfs
Testing
1 brick simple volume
From node dc2-3-35, 1Gb ethernet, Intel(R) Xeon(R) CPU X5355 @ 2.66GHzTest used 6 simultaneous IO threads. Tests below each specify a different record size for the test and are otherwise identical.
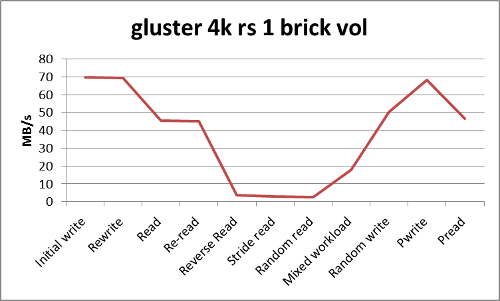
iozone -t6 -Rb gfs_general_4.xls -P1 -r4k -s32G -F /mnt/gfs/io1.test /mnt/gfs/io2.test /mnt/gfs/io3.test \ /mnt/gfs/io4.test /mnt/gfs/io5.test /mnt/gfs/io6.test
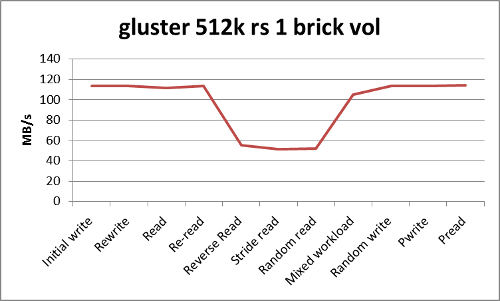
iozone -t6 -Rb gfs_general_512.xls -P1 -r512k -s32G -F /mnt/gfs/io1.test /mnt/gfs/io2.test /mnt/gfs/io3.test \ /mnt/gfs/io4.test /mnt/gfs/io5.test /mnt/gfs/io6.test
6 brick distributed replicated
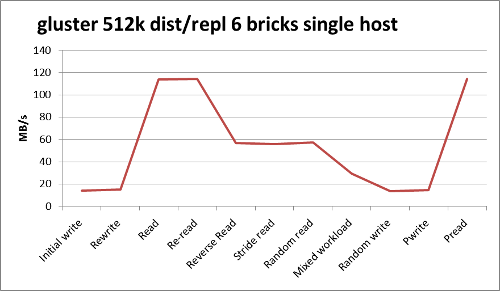
This test was done from a client machine with 10Gb network interface (gluster test server has 10G interface in all tests).iozone -t6 -Rb gfs_dr_10G_general_512.xls -P1 -r512k -s32G -F /mnt/gfs/io1.test /mnt/gfs/io2.test /mnt/gfs/io3.test /mnt/gfs/io4.test /mnt/gfs/io5.test /mnt/gfs/io6.test


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
gfs_dr_10G_general_512.png | manage | 31 K | 27 Jun 2012 - 20:26 | BenMeekhof | Iozone general test 512k recordsize with 6 threads,distributed replicated volume, 10G client |
| |
gfs_dr_10G_general_512.xls | manage | 27 K | 27 Jun 2012 - 20:41 | BenMeekhof | |
| |
gfs_general_1.xls | manage | 32 K | 27 Jun 2012 - 20:41 | BenMeekhof | |
| |
gluster-4k-test1.png | manage | 33 K | 21 Jun 2012 - 14:09 | BenMeekhof | Iozone general test 4k recordsize with 6 threads |
| |
gluster-512k-test1.png | manage | 31 K | 21 Jun 2012 - 14:09 | BenMeekhof | Iozone general test 512k recordsize with 6 threads |
Edit | Attach | Print version | History: r6 < r5 < r4 < r3 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r6 - 27 Jun 2012, BenMeekhof

{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback