CEPH cluster setup
Docs
http://ceph.com/docs/master/install/manual-deployment/
System Provisioning
CFengine
Updated cfengine trunk to accommodate SL7 systems.
Created cfengine policy in branch "ceph" following basic manual provisioning steps. Effects CEPH, CEPH_OSD, CEPH_MDS, CEPH_MON, and/or CEPH_OG as appropriate. These acronyms will make sense to you after you read the ceph docs.
- configures repos (not mirrored)
- installs packages
- copies /etc/ceph/ceph.conf from stash/ceph
- creates /var/lib/ceph/mon/$(name)-$(mon). $(name) is cluster name 'ceph', $(mon) is system hostname. Started with just "cephmon01".
- populates /var/lib/ceph/bootstrap-mds and bootstrap-osd on all CEPH class hosts with ceph.keyring. This was obtained from corresponding location on cephmon01 after following monitor bootstrap process from manual install docs and copied into stash/ceph/bootstrap-mds and bootstrap-osd.
- Installs /root/tools/ceph-disk-prepare on hosts in class CEPH_OSD. This simple script run locally on each OSD runs ceph-disk prepare (and activate) on a range of disks.
OS Build
Systems built using cobbler profile server-large-sl7. Configured with active-standby bonds using 10G interface as primary.
Network interfaces in RHEL7 get named with predictable names. We're already familiar with the scheme for Dell systems on EL6 (em1, p1p1, etc). For older systems it now falls back to a PCI-bus id scheme. Non-dell systems that have new enough SMBios may get a different scheme. Full information on the naming logic is here:
https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Networking_Guide/ch-Consistent_Network_Device_Naming.html
For umtestXX they end up with PCI-bus naming scheme. Here is an example from umtest04 of mapping PCI location to network device name.
| lspci output | device name |
|---|
|
05:00.0 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
|
enp5s0f0 |
|
05:00.1 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
|
enp5s0f1 |
|
1b:09.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5704 Gigabit Ethernet (rev 03)
|
enp27s9f0 |
|
1b:09.1 Ethernet controller: Broadcom Corporation NetXtreme BCM5704 Gigabit Ethernet (rev 03)
|
enp27s9f1 |
systemd/udevd will also name devices according to the DEVICE= line in ifcfg-XXXX if the MACADDR line matches. So, it is quite possible to cause devices to be named exactly as before or even with any arbitrary string.
Ceph configuration
For the monitor system cephmon01, manual monitor bootstrap instructions were followed after applying the cfengine policy to setup directories and config file. That config file is at the end of this document for reference but the up-to-date version is at
https://ndt.aglt2.org/viewvc/cfengine/branches/ceph/masterfiles/stash/ceph/
For the OSD systems, they were provisioned and configured with policy from ceph branch. Then used /root/tools/ceph-disk-prepare to create xfs or btrfs filesystems. At the moment, disks on umtest01 are btrfs. The rest are XFS. The --test argument causes the script to print but not do. Replace argument 'ondisk' with a separate journal device if using. The ceph-disk util will automatically create a new 10GB partition for each osd on the journal device.
[root@umtest01 tools]# ./ceph-disk-prepare btrfs /dev/sd a p ondisk --test
ceph-disk prepare --cluster ceph --cluster-uuid db861c04-b855-4f47-8d25-c6e28d24a1e2 --fs-type btrfs /dev/sda
ceph-disk activate /dev/sda
ceph-disk prepare --cluster ceph --cluster-uuid db861c04-b855-4f47-8d25-c6e28d24a1e2 --fs-type btrfs /dev/sdb
ceph-disk activate /dev/sdb
... etc through sdp.
| Test System Summary |
|---|
| umtest01 | 8 x 500GB Btrfs | 2 x AMD Opteron 285 dual core, 16GB RAM (16 disks in system) |
| umtest03 | 8 x 750GB XFS, Journal device at disk 8 256GB OCZ-VERTEX4 SSD (/dev/sdh) (23 + 1 ssd disks in system) | 2 x AMD Opteron 285 dual core, 8GB RAM |
| umtest04 | 8 x 750GB XFS on two controllers. | 2 x AMD Opteron 285 dual core, 12GB RAM (24 disks in system) |
The ceph docs recommend 1 CPU core per OSD, and ~1GB for 1TB of storage per daemon. When I tried to run the above systems in a cluster using 16 or 24 disks it would work to build the cluster, and work for light operations. As soon as any failure event occurred, such as power interruption, it was impossible to recover the cluster. No matter how I tried to arrange restarting OSD at some point the resource needs for re-establishing a clean state would overwhelm resources available on each host and OSD would begin randomly going down due to timeouts. Then the process would have to start over, etc, etc. So...pay attention to minimum hardware requirements (link below). I took a chance that for a test situation 2 disks per core would be ok without bringing things to a halt as when I had configured all 16 or 24 disks on each system.
UPDATE: This configuration seems to be ok - we can pull the plug on one system and when it comes up the OSD are placed back into the cluster quickly and without the performance lags and timeouts seen when more OSD are configured per system. This iteration of the cluster also has fewer placement groups. Only 128 per pool are configured. With four Openstack pools created this makes for 512 placement groups on the whole cluster. There is some room yet for more pools in this config. The cluster as configured with 24 OSD should not exceed 2048 PG. Each PG is cpu-intensive so in any configuration we not only have to be careful of OSD per CPU/Memory but also of total PG. The cluster will go to state HEALTH_WARN if there are more than a certain number of PG per OSD (100 I believe).
Hardware requirements:
http://ceph.com/docs/master/start/hardware-recommendations/
More on PG:
http://ceph.com/docs/master/rados/operations/placement-groups/#preselection
Ceph administration
Login to node cephmon01/02/03 (only cephmon01 exists today). This is not the place to learn about ceph commands, but one exciting one is "ceph -s" where you can see that the cluster is in state "HEALTH_OK". Another exciting one is "ceph osd tree" to see all hosts and osd. For other commands related to adding/removing OSDs I'd recommend referencing the docs:
http://ceph.com/docs/master/rados/
There are some useful commands:
/root/tools/ceph-disk-prepare xfs /dev/sd a e ondisk |
Usage further explained above, for provisioning new OSD disks singly or in batch. Run without arguments for help |
ceph osd out <osd-id> |
Take OSD out of cluster. Perhaps for maintenance, etc. Also use before removing an OSD. Use "ceph osd in " to return to service. |
/root/tools/ceph-osd-rm <osd-id> |
Permanently remove OSD from crush map, auth map, and cluster (3 commands in script). To put back requires re-init of OSD with ceph-disk prepare. Typically would use if replacing an OSD with some other hardware or needing to re-create OSD from scratch for some reason. |
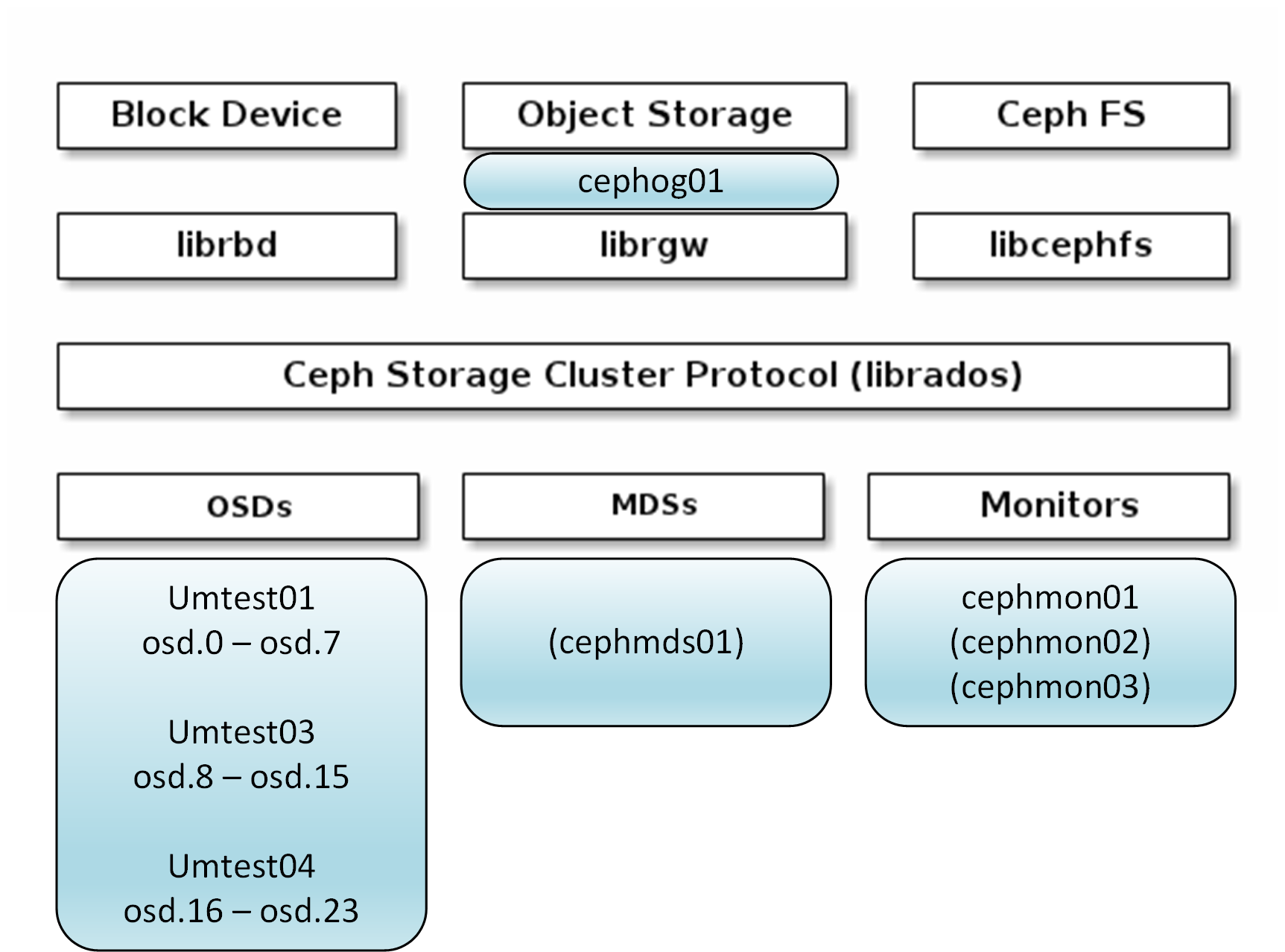
High level diagram of hosts in our cluster (all .aglt2.org):
Sample ceph.conf (3/27/2015)
[global]
fsid = db861c04-b855-4f47-8d25-c6e28d24a1e2
mon initial members = cephmon01
mon host = 192.41.231.175
public network = 192.41.230.0/23
cluster network = 10.10.0.0/22
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd journal size = 10280
filestore xattr use omap = true
# How many times to write an object. 3 is the default.
osd pool default size = 3
# replicas allowed for writes in degraded state
osd pool default min size = 2
osd pool default pg num = 2048
osd pool default pgp num = 2048
#0 for a 1-node cluster.
#1 for a multi node cluster in a single rack
#2 for a multi node, multi chassis cluster with multiple hosts in a chassis
#3 for a multi node cluster with hosts across racks, etc.
osd crush chooseleaf type = 1
[osd]
journal zero on create = true
[mds.01]
host = cephmds01
[mon.cephmon01]
host = cephmon01
mon addr = 192.41.231.175:6789
--
BenMeekhof - 27 Mar 2015



{kind=link}