|
|
You are here: Foswiki>AGLT2 Web>ImplementingQoSatAGLT2 (05 Jul 2012, TomRockwell)Edit Attach
Implementing Network QoS at AGLT2
Recently we have seen periods where our LANs have been congested and packets are dropped. This has resulted in some of the monitoring data we collect having gaps and (worse) some of the running jobs failing withlost-heartbeat failures.
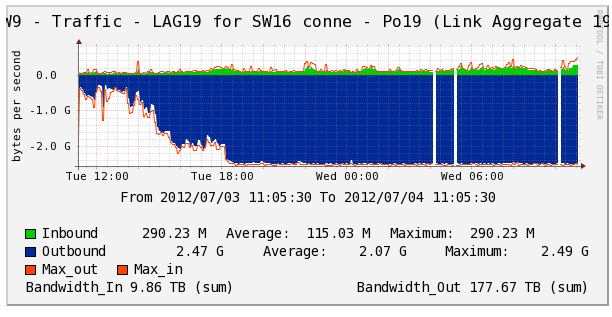
Below is an example of the a congested link (the LAG on port-channel 19 between SW9 and SW16) and results on the Condor job monitoring.
To see if we can address this issue we want to prioritize traffic to/from the following service nodes: - umopt1.aglt2.org (Condor headnode) with private IP 10.10.1.3
- gate01.aglt2.org (USATLAS gatekeeper) with private IP 10.10.1.11
- gate02.grid.umich.edu (Grid gatekeeper for no USATLAS) with private IP 10.10.1.12
- head01.aglt2.org (dCache headnode for all but namespace) with private IP 10.10.1.41
- head02.aglt2.org (dCache namespace headnode) with private IP 10.10.1.45
Lost Heartbeat Jobs
We seem to hit lost-heartbeat jobs when the network is congested. I explored one of them (see PANDA http://panda.cern.ch/server/pandamon/query?job=1538734258 ). The only log file I can find has the following information:000 (38513249.000.000) 07/04 11:26:35 Job submitted from host: <130.199.54.60:58958> pool:ANALY_AGLT2 ...
017 (38513249.000.000) 07/04 07:26:46 Job submitted to Globus RM-Contact: gate01.aglt2.org/jobmanager-condor JM-Contact: https://gate01.aglt2.org:55788/2466831/1341401201/ Can-Restart-JM: 1 ...
027 (38513249.000.000) 07/04 07:26:46 Job submitted to grid resource GridResource: gt2 gate01.aglt2.org/jobmanager-condor GridJobId: gt2 gate01.aglt2.org/jobmanager-condor https://gate01.aglt2.org:55788/2466831/1341401201/ ...
001 (38513249.000.000) 07/04 07:31:49 Job executing on host: gt2 gate01.aglt2.org/jobmanager-condor ...
029 (38513249.000.000) 07/04 08:04:58 The job's remote status is unknown ...
030 (38513249.000.000) 07/04 08:13:45 The job's remote status is known again ...
005 (38513249.000.000) 07/04 12:07:54 Job terminated. (1) Normal termination (return value 0) Usr 0 00:00:00, Sys 0 00:00:00
- Run Remote Usage Usr 0 00:00:00, Sys 0 00:00:00
- Run Local Usage Usr 0 00:00:00, Sys 0 00:00:00
- Total Remote Usage Usr 0 00:00:00, Sys 0 00:00:00
- Total Local Usage
It seems this pilot picked up a second job after the original job failed. This second job finished OK (See http://panda.cern.ch/server/pandamon/query?job=1538746841 )
- - Run Bytes Sent By Job
- - Run Bytes Received By Job
- - Total Bytes Sent By Job
- - Total Bytes Received By Job
Configuring QoS for SW9 and SW16
Using the information in the introduction above we will try to protect traffic to/from those critical servers. It seems the simplest means of doing this is to setup the "source" network port to have the QoS COS set. The critical servers are all VMware systems. I created a new network resource allocation called "AGLT2 Management Servers" and set the following attributes on it: Physical Adapter Share: High QoS Priority Tag: 4 I had to enable "Overrides" for the Resource Allocation on the following port-groups: AGLT2, AGLT2_Private and Grid. I could then set the public and private "Resource Allocation" on the distributed vSwitch ports for the LFC, GATE01, GATE02, HEAD01, HEAD02 and UMOPT1 (Condor). -- ShawnMcKee - 04 Jul 2012- Condor monitoring showing the impact of a congested LAG on SW9 port-channel 19:
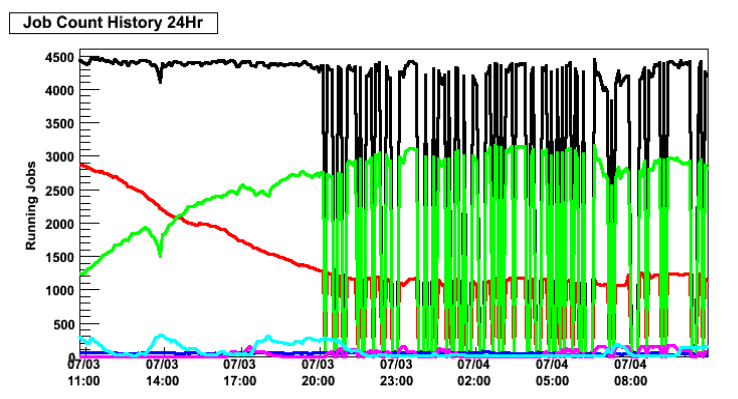
- Cacti plot of the traffice on LAG 19 on SW9 showing congestion:


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
LAG19_congested.png | manage | 37 K | 04 Jul 2012 - 15:57 | ShawnMcKee | Cacti plot of the traffice on LAG 19 on SW9 showing congestion |
Edit | Attach | Print version | History: r4 < r3 < r2 < r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r4 - 05 Jul 2012, TomRockwell

{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback